随着大数据时代的深入发展,海量非结构化数据的存储、管理与高效检索成为企业数字化转型的核心挑战。TRS全文数据库服务器解决方案,作为一套成熟、稳定且高性能的数据存储服务体系,正是为应对这一挑战而设计。它超越了传统关系型数据库的局限,专注于文本、文档、图片、音视频等非结构化数据的全生命周期管理,为企业构建知识资产的核心仓库提供了强大引擎。
一、 解决方案核心架构
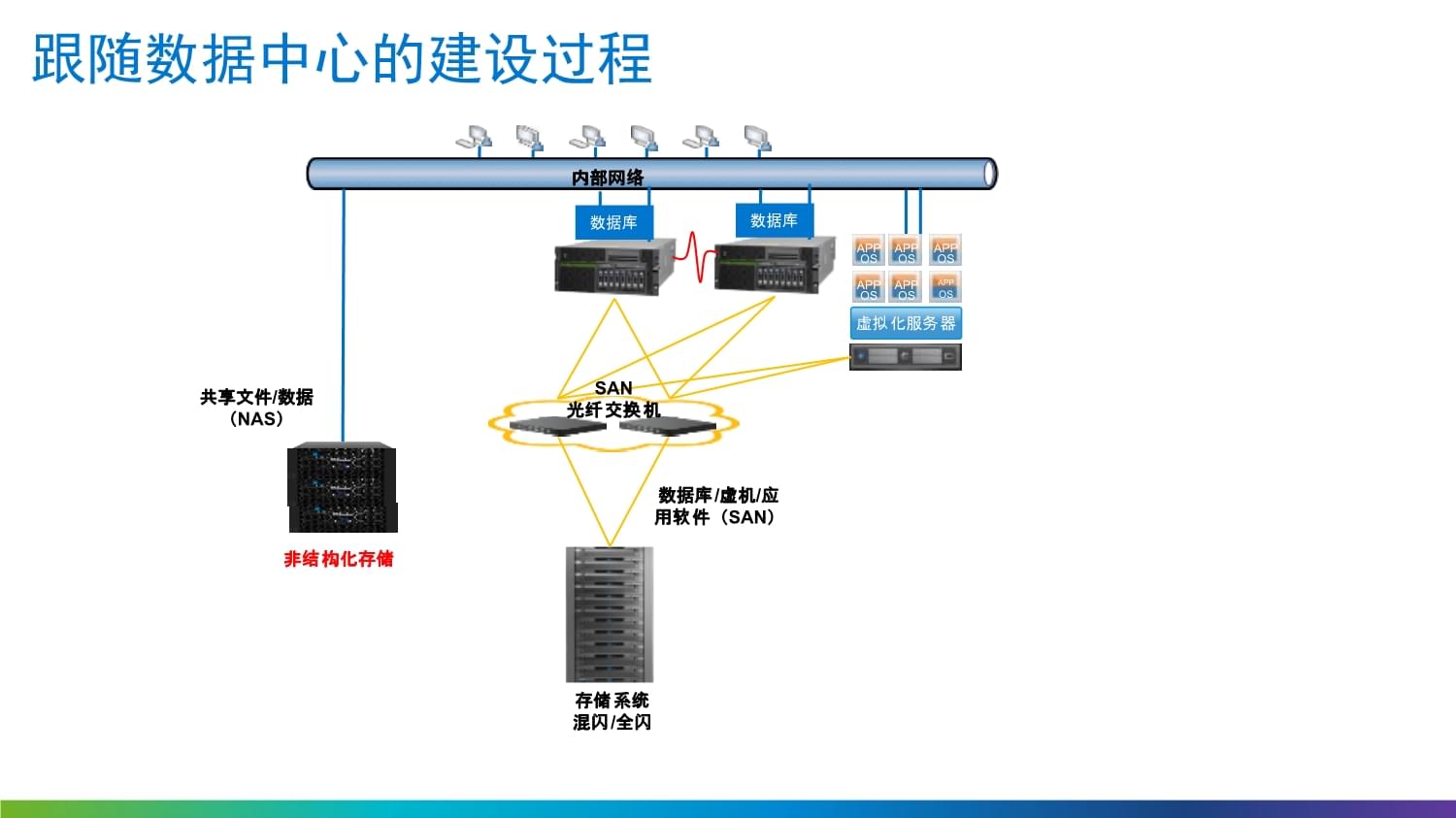
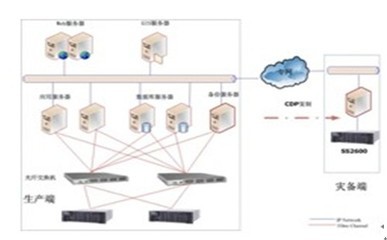
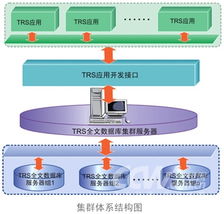
TRS全文数据库服务器采用先进的分层架构设计,逻辑上可分为数据接入层、核心引擎层、服务接口层和运维管理层。
- 数据接入层:支持多源异构数据的广泛接入。无论是来自业务系统的实时数据流、历史文档的批量导入,还是对互联网信息的定向采集,都能通过丰富的适配器与接口轻松完成,实现数据的“一站式”汇聚。
- 核心引擎层:这是解决方案的“心脏”。它集成了高性能的全文检索引擎、智能中文分词系统、多维索引结构以及高效的缓存机制。其独创的索引技术,不仅能对文本内容进行毫秒级的关键词、短语、布尔逻辑组合检索,更能支持对文档属性(如作者、日期、分类)的结构化查询,实现精准的“大海捞针”。
- 服务接口层:提供标准化的API(如HTTP RESTful API、SDK等),确保上层应用(如知识管理系统、内容管理平台、智能客服系统、垂直搜索引擎)能够方便、灵活地调用底层的存储与检索服务,实现快速集成与业务创新。
- 运维管理层:配备完善的图形化监控与管理工具,可对数据库集群的运行状态、性能指标、存储容量、安全日志进行实时监控与智能分析,保障系统7x24小时稳定可靠运行,极大降低了运维复杂度。
二、 数据存储服务的核心优势
TRS全文数据库服务器的数据存储服务,其卓越性体现在以下几个关键方面:
- 海量数据承载能力:采用分布式架构设计,支持横向线性扩展,可通过增加节点轻松应对PB级别的数据增长,满足未来业务扩展需求,避免数据孤岛和性能瓶颈。
- 高性能智能检索:基于倒排索引与先进的排名算法,在亿级数据规模下仍能保证亚秒级的查询响应速度。支持同义词扩展、模糊检索、语义关联等智能检索功能,显著提升查全率与查准率,让数据“易找好用”。
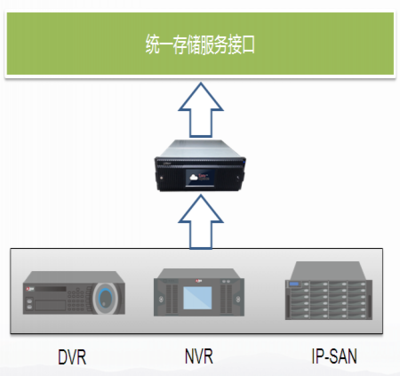
- 多模态数据统一管理:不仅存储文本,还能有效管理文档的元数据,并与附件(如PDF、Word、图片、音视频)建立关联索引,实现“内容”与“文件”的统一管理和关联检索,真正形成企业知识图谱的底层支撑。
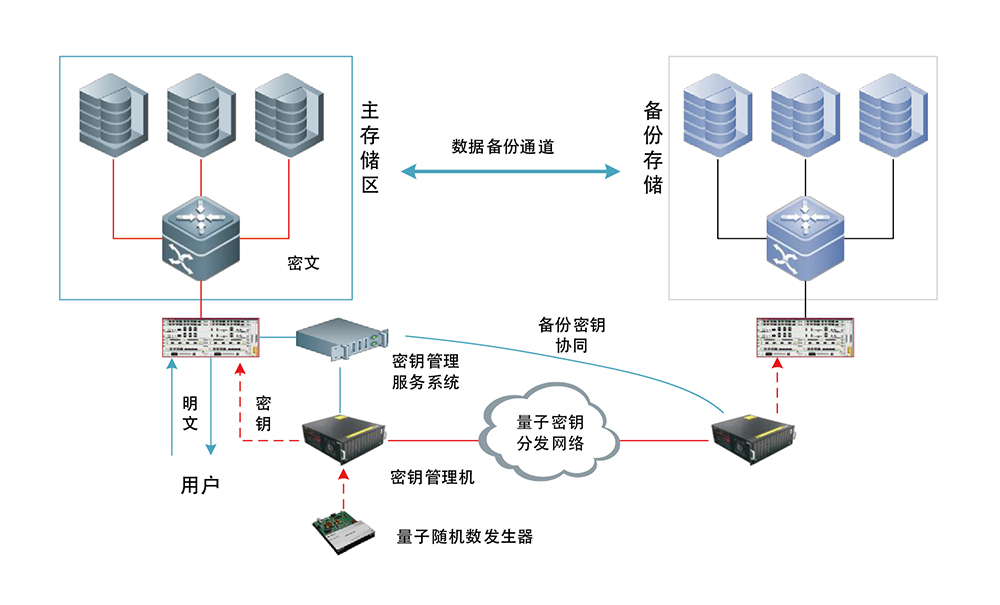
- 高可靠与安全性:提供数据多副本存储、自动故障切换、定时备份与恢复机制,确保数据零丢失与服务高可用。在安全方面,具备完善的权限控制体系,支持字段级、记录级的访问控制,并与企业现有身份认证系统无缝集成,保障核心知识资产的安全。
- 开放的生态兼容性:支持主流操作系统与国产化软硬件环境,能够与企业现有的IT基础设施(如虚拟化平台、云环境)平滑兼容,保护既有投资,降低部署风险。
三、 典型应用场景
TRS全文数据库服务器解决方案的数据存储服务已广泛应用于诸多关键领域:
- 政府与公共事业:构建政策法规库、档案管理系统、一体化政务服务平台,实现海量公文、档案、便民信息的统一管理与高效服务。
- 金融与法律:用于案例库、合同库、研报库的构建,支持律师、分析师进行快速文献调研与风险排查。
- 媒体与出版:作为数字资产管理系统(DAM)或内容管理系统(CMS)的核心存储,管理新闻稿件、历史报刊、图书音像等数字内容。
- 大型企业与科研机构:建立企业知识库、技术文档库、竞争情报系统,盘活隐性知识,赋能研发创新与决策支持。
###
TRS全文数据库服务器解决方案提供的数据存储服务,是一个集海量存储、智能检索、安全可靠与易于管理于一体的企业级基础软件平台。它不仅仅是数据的“容器”,更是激活数据价值、驱动业务智能的“转化器”。选择TRS,意味着为企业构建了一个面向未来的、坚实的数据基石,助力企业在数据驱动的竞争中赢得先机。